The rise of Large Language Models (LLMs) and Generative AI has brought a new necessity to the data landscape: the ability to understand and search data based on meaning rather than just keywords. This is where vector stores come in, and Redis—the fast, in-memory data structure store—has emerged as a powerful and high-performance contender in this space.
In this article, we’ll dive into what the Redis vector store is, when you should harness its speed, and how the underlying technology makes semantic search lightning-fast.
What is the Redis Vector Store?
Redis, traditionally known as a blazing-fast key-value store used for caching and session management, transforms into a full-fledged vector database through its RediSearch module.
A vector store is fundamentally designed to store, manage, and query high-dimensional vectors. These vectors, called embeddings, are numerical representations of complex, unstructured data like text, images, or audio. They are created by Machine Learning models (like BERT or OpenAI’s embeddings models) and are positioned in a multi-dimensional space such that items with similar meaning or context are placed closer together.
The Redis Vector Store combines Redis’s core advantages—in-memory speed and low latency—with the advanced indexing and search capabilities provided by RediSearch. This allows developers to perform real-time, semantic similarity searches across vast datasets.
Key Components:
Redis Core: Provides the high-speed, in-memory architecture for storing the vector and associated metadata.
Vector Embeddings: The numerical arrays (lists of numbers) that encode the semantic meaning of your data.
RediSearch Module: This module adds the crucial functionality for creating secondary indexes and executing vector similarity search queries.
When to Use the Redis Vector Store
Choosing Redis as your vector store is primarily a decision driven by speed, real-time needs, and the desire for a unified data platform.
1. Retrieval Augmented Generation (RAG) Systems
This is arguably the most common and compelling use case. RAG is an architectural pattern that improves LLM responses by grounding them with external, domain-specific data.
The Redis Advantage: In a RAG pipeline, the user’s query is converted to a vector and used to retrieve the most relevant context chunks from the vector store. Since this retrieval step must happen in real-time for every user question, Redis’s sub-millisecond latency for vector search is critical for a fast user experience.
Beyond Vectors: Redis can also be used for Semantic Caching (caching common query results) and LLM Memory (storing conversation history) in the same application, unifying the data layer.
2. High-Performance Semantic Search
If your application requires finding information based on context and meaning rather than simple keyword matches, and it demands low-latency results, Redis is an excellent choice.
Examples: E-commerce product search (finding “a cozy place to sleep” returns blankets and pillows, not just results with the word “sleep”), legal document retrieval, or knowledge base search.
3. Hybrid Search and Metadata Filtering
Many advanced search applications need to combine vector similarity with traditional keyword or filter queries (e.g., “Find documents similar to ‘budget plan’ AND published after 2024″).
The Redis Advantage: Because Redis stores the vector alongside the original data and metadata (in Hash or JSON data types), you can create indices that allow you to efficiently filter on non-vector fields (like date, author, or category) before or during the vector search. This is known as Hybrid Search.
4. Recommendation Systems
For real-time personalization, a vector store can quickly find items or users whose preference vectors are similar to the current user’s profile.
Examples: Recommending a movie based on the semantic vector of a movie the user just watched, or suggesting a song based on the vector of a user’s current playlist.
How the Underlying Tech Works: Vector Similarity Search
The magic of the Redis vector store lies in its ability to execute Vector Similarity Search (VSS) with immense speed. This process can be broken down into three core steps:
1. Embedding and Storage
Data Transformation: Unstructured data (text, images, etc.) is passed through an embedding model (e.g., Sentence Transformers, OpenAI’s models).
Vector Creation: The model outputs a high-dimensional vector (e.g., 768 or 1536 floating-point numbers) that mathematically represents the data’s meaning.
Storage: Redis stores this vector along with its associated metadata (the original text, a document ID, a timestamp, etc.) in a Redis data structure (typically a Hash or JSON document).
2. Indexing for Fast Retrieval
Instead of comparing the query vector to every single vector in the database (a slow, brute-force search), Redis creates a specialized index to speed up the process. This index is a major component of the RediSearch module.
Approximate Nearest Neighbor (ANN) Algorithms: Since finding the absolute nearest neighbor across millions of dimensions is computationally expensive, vector databases use ANN algorithms to quickly find vectors that are close enough.
Hierarchical Navigable Small World (HNSW): This is the most common and powerful algorithm used by Redis.
HNSW creates a multi-layered graph structure. The top layers contain nodes that are sparsely connected (representing large jumps across the vector space), while the lower layers contain dense connections (representing local similarity).
Search starts at the top, quickly traversing the sparse layer to get to the neighborhood of the target vector, and then drops down to the denser layers to find the final nearest neighbors. This dramatically reduces the number of distance calculations needed, leading to extremely fast query times.
3. Calculating Similarity
Once the index narrows down the candidate vectors, the actual similarity is calculated using a distance metric. Redis supports popular metrics, including:
Cosine Similarity: Measures the angle between two vectors. A score closer to 1 means they are highly similar.
Euclidean Distance (L2): Measures the straight-line distance between two vectors. A smaller distance means higher similarity.
Inner Product (IP): Useful for finding vectors that have both a similar direction and a large magnitude.
The results are then ranked by the similarity score and the top-K (e.g., top 5) closest vectors are returned to the application, providing the most semantically relevant context in real-time.
Redis’s evolution into a robust, high-performance vector store cements its role as a versatile powerhouse in modern application architectures. By leveraging its in-memory speed and the advanced indexing of RediSearch, it provides a critical, low-latency foundation for the next generation of AI-driven applications.
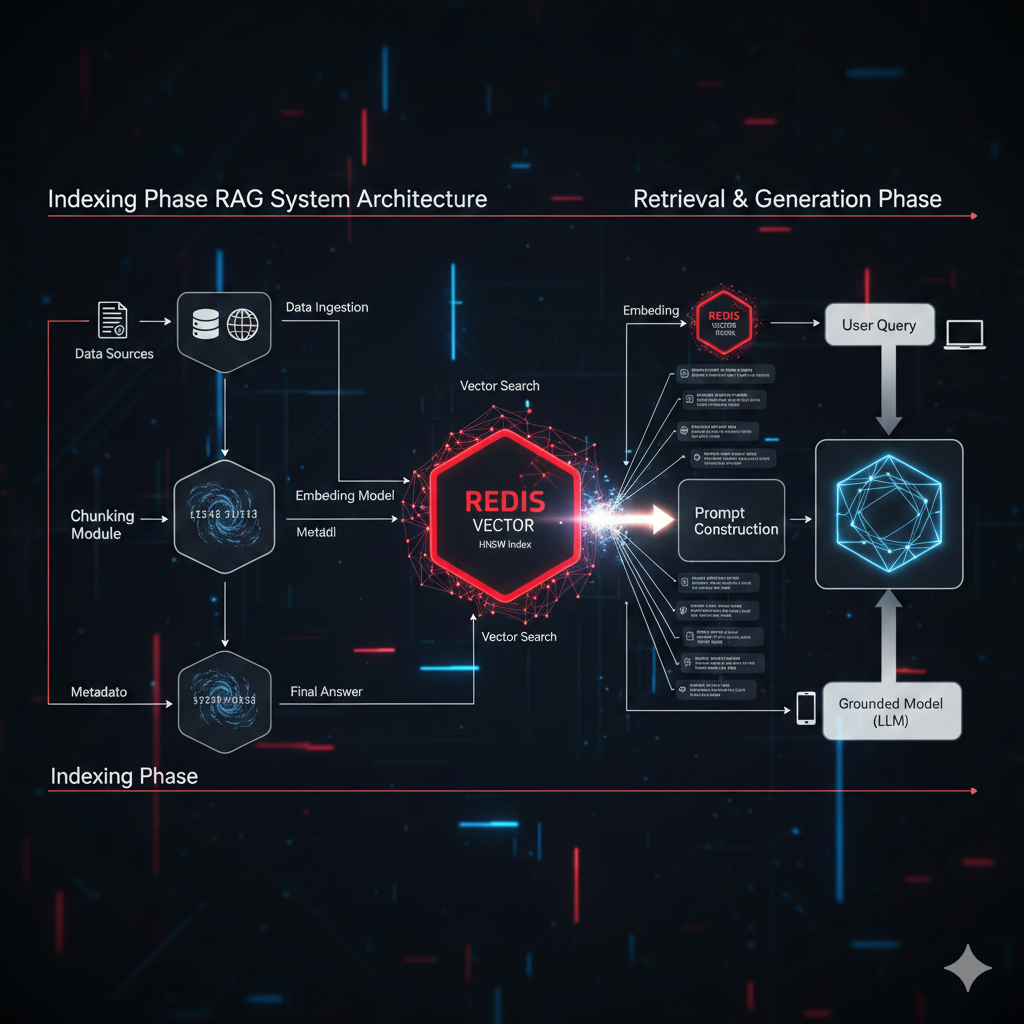
Retrieval-Augmented Generation (RAG) with Redis
The RAG pattern is a powerful way to make LLMs more accurate, relevant, and trustworthy by providing them with specific, external knowledge (like your company documents, internal manuals, or up-to-date information).
Here is a breakdown of the RAG architecture and how Redis plays its part in the two main phases: Indexing and Retrieval.
Phase 1: Indexing (Populating the Vector Store)
This phase happens offline and involves preparing your domain-specific data for search.
Data Ingestion: Start with your unstructured data sources (PDFs, internal wiki pages, database records, etc.).
Chunking: The data is broken down into smaller, manageable pieces (chunks) of text. This is crucial because shorter, focused chunks yield more precise search results.
Embedding Generation: Each text chunk is fed into an Embedding Model (e.g., a transformer model). This model translates the meaning of the text into a numerical vector.
Vector Storage in Redis: The generated vectors are stored in the Redis Vector Store (using the RediSearch module). Importantly, the store also keeps the original text chunk and relevant metadata (like document title, author, date, etc.) associated with the vector. This is the search index.
Key Role of Redis: Redis provides the high-speed, durable storage and the specialized HNSW index required for the retrieval phase.
Phase 2: Retrieval and Generation (The Real-Time Query)
This phase happens every time a user submits a query to your application.
User Query: A user asks a question (e.g., “What is the policy for remote work?”).
Query Embedding: The user’s question is passed through the exact same Embedding Model used during the Indexing phase to convert it into a query vector.
Vector Search in Redis (Retrieval): The query vector is sent to the Redis Vector Store.
Redis uses its HNSW index to quickly perform an Approximate Nearest Neighbor (ANN) search.
It finds the top K (e.g., 5-10) vectors that are most semantically similar to the query vector.
It retrieves the original text chunks (the “context”) associated with these closest vectors.
Prompt Construction: The retrieved context chunks are combined with the original user query and a set of instructions (Prompt) into a single, comprehensive prompt.
LLM Generation: This enhanced prompt is sent to the Large Language Model (e.g., GPT-4, Gemini).
Grounded Response: The LLM uses the provided, domain-specific context from Redis to generate a factual, accurate, and relevant answer.
Final Answer: The LLM’s final response is returned to the user.
Key Role of Redis: The extremely fast retrieval (Step 3) ensures the entire RAG pipeline runs with low latency, making the application feel responsive and real-time.
This architectural approach effectively turns Redis into the knowledge conduit that connects the general intelligence of the LLM with the specific, proprietary knowledge base of your organization.